Brightics란?
www.brightics.ai/kr 를 참고해주세요
이 포스팅은 삼성SDS의 브라이틱스 솔루션을 사용할 때 활용할 수 있는 꿀팁에 대한 내용입니다. 꿀팁 뿐만 아니라 사용하면서 주의해야할 점들도 다루었습니다. 솔루션을 사용하다가 필요한 부분을 참고하시면 됩니다. 초보자용 꿀팁이므로 숙달된 분들에게는 꿀팁이 아닐수도 있습니다 ^^
String Summary
- 인풋 데이터의 타입이 String 인 경우에만 Input Column에서 선택가능한 컬럼으로 뜹니다. 예를 들어 Double 로 되어 있는 경우 Select 눌려서 나오는 팝업창에 뜨지 않습니다. Double 같은 타입은 Statistic summary를 사용하면 됩니다.
Statistic Summary
- 숫자 등 데이터에 대한 평균 등을 구하는 함수입니다.
Add Data 작업 시
날짜 관련은 String으로 읽는 것이 좋습니다.
그래야 나중에 날짜 관련 함수를 사용하기 편합니다.

Filter 작업 시
Condition 에서 문자열에는 작은따옴표를 사용해줍니다. 큰따옴표는 에러가 납니다.

Transpose
행렬바꾸는 함수입니다. 옆으로 펼치고 싶은 컬럼을 input에 넣습니다. 컬럼으로 올릴 값은 label에 넣습니다.
아래의 예시를 보면 더 명확해집니다. 왼편이 오른편의 데이터로 바뀝니다.

Two Sample t-test 에서 First 와 Second
First와 Second에 넣는 값은 1인지 1.0인지도 체크해서 동일하게 넣어줘야 합니다.
이걸 만약 다르게 넣은 경우 에러메시지는 divison by zero로 표시될 수도 있습니다.

데이터를 볼 때 데이터 조회개수 제한에 유의하자
전체 데이터는 예를 들어 6천5백개인데 Show rows에 1천개로 제한되어 있는 상태는 아닌지 유의해야 합니다.
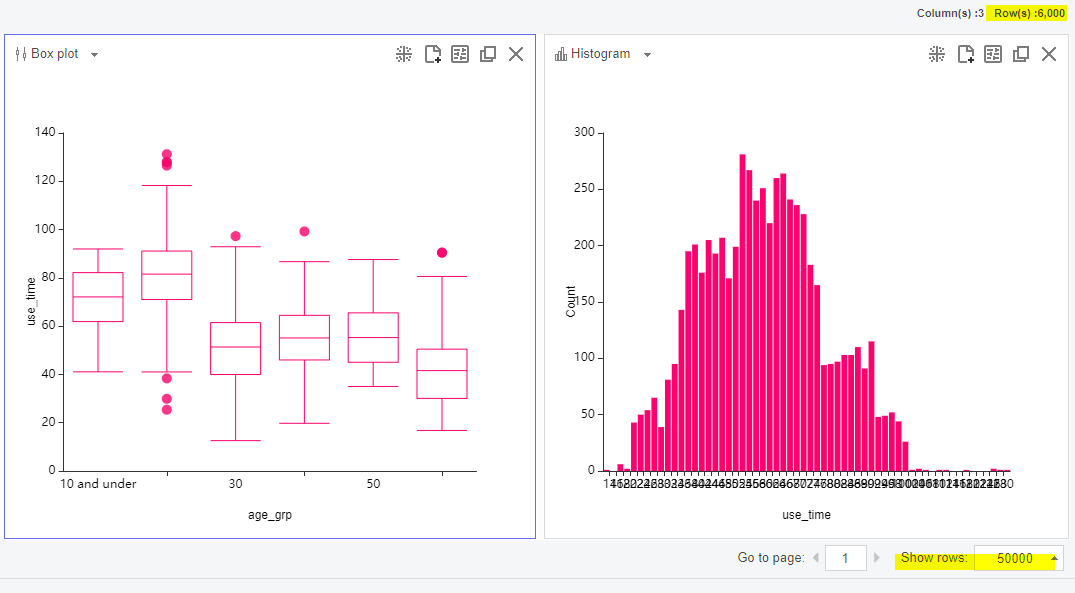
Bartlett's test, One Way ANOVA, Tukey's Range test 검정 시 유의점
RESPONSE COLUMNS에 들어가는 컬럼에는 NULL이 없도록 해줘야 합니다.
검정을 돌리기 전에 DELETE MISSING DATA를 해줍시다

Unpivot 사용 예시
가로로 쭉 늘어져 있는 데이터를 세로로 쌓을 수 있습니다
values 에는 데이터 값이 될 컬럼을 넣어줍니다
identifiers에는 남아있어야 하는 컬럼을 넣어줍니다

Add Function Column 사용 예시
load 할 때 왼편의 year 컬럼 데이터가 double 이었지만 마치 string 인 것처럼 인식하고 작동해주었습니다.

Select Column 함수 꿀팁
load할 때 까먹었다 하더라도 데이터 타입을 변경할 수 있습니다.
컬럼의 이름도 바꿀 수 있습니다.
Add Lead Lag 함수 설명
데이터를 한 칸씩 밀거나 당길 수 있는 함수입니다.
offset set 에는 몇 칸을 밀거나 당길건지 설정하는 부분입니다.
양수 또는 음수를 넣으면 됩니다.
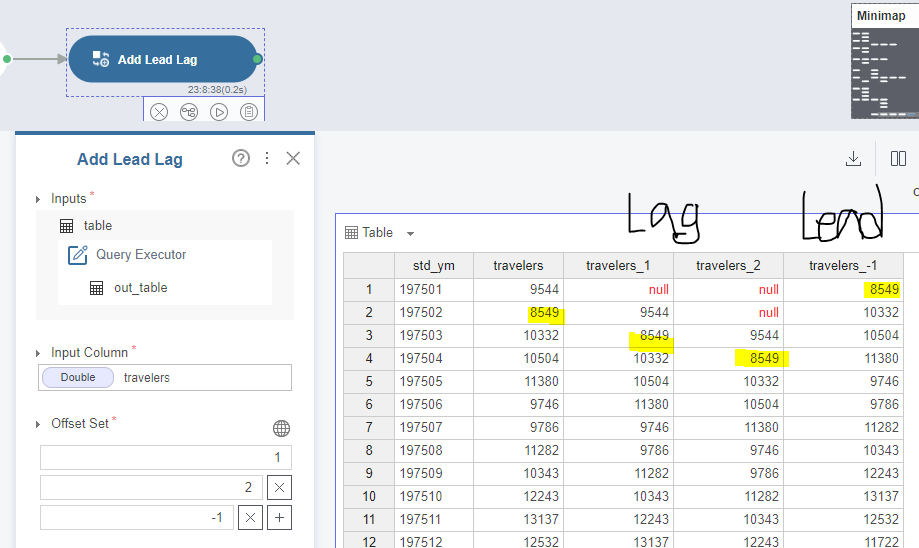
양수를 넣으면 Lag를 만들어줍니다. 한 칸 씩 뒤로 밀립니다.
음수는 Lead를 만듭니다. 한 칸씩 위로 올려줍니다.
밀어올려진 데이터는 그냥 사라집니다. 예를 들어 lead 에서 9544 는 그냥 없어집니다. Lead의 맨 밑의 행에서 해당 부분은 null이 되었을 것입니다.
Moving Average 함수 설명
Weights 는 가중평균 관련 설정입니다. uniform weights를 선택하면 동일하게 가중치를 주고, custom weights를 선택하면 직접 가중치를 설정할 수 있습니다. window size의 경우 주변의 몇 칸 까지 계산에 넣을 지를 설정하는 부분입니다. mode 설정은 두 가지 인데, past values only를 자주 쓰게 될 겁니다. 이것은 과거 값들로만 이동평균값을 구하겠다는 뜻인데요, centered moving average를 만약에 선택하고 window size는 아래 그림처럼 3을 해두면 앞뒤로 3칸을 이동평균값을 구하는데 사용하겠다는 뜻이 됩니다. 아래 그림에서는 과거 값 3개만 계산에 포함되도록 설정했기 때문에 travelers_ma 컬럼에서 맨 앞의 2 개 칸은 계산할 3개 칸이 없기 때문에 null로 보이게 됩니다.

Association Rule 함수 관련
인풋 타입에서 user - single item 은 아래 캡쳐 처럼 하나의 컬럼 안에 하나의 데이터가 들어가 있는 경우에 사용하면 됩니다. 만약 하나의 컬럼 안에 여러 개의 데이터가 예를 들어 clothing;sports wear;food 이런 식으로 들어가있는 경우라면 user - multiple items 를 사용해주어야 합니다.
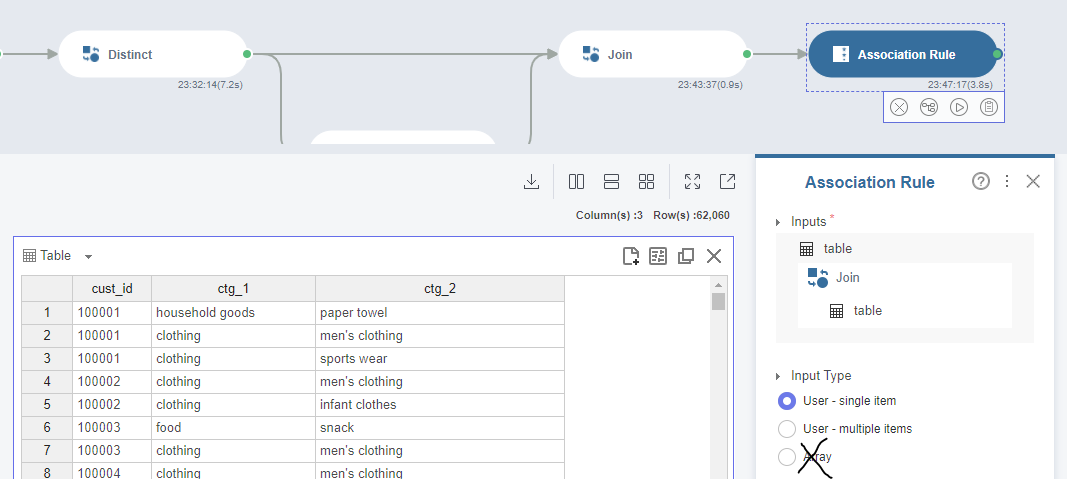
연관분석의 결과값을 해석할 때 주의할 점은 A-B 와 B-A는 다른 룰이라는 점입니다. 아래 캡쳐에서 1번째 행과 2번째 행은 같은 룰이라고 착각하기 쉽습니다. 아래 예시에서 심지어 lift 값도 같지만 둘은 엄연히 다른 규칙입니다.

참고로 lift 는 1 이상일 때 의미가 있고, 값이 높을수록 좋습니다.
연관분석은 전처리가 중요합니다.
연관분석의 전제는 2건 이상 구매했을 때 분석이 가능하기 때문에, 아래 캡쳐 속의 100010 번 고객의 경우 처럼 1개만 구매한 고객은 분석 대상 데이터셋에서 제외시켜주는 전처리가 필요합니다.

'IT,SW,Data,Cloud,AI' 카테고리의 다른 글
| 빅데이터분석기사 필기 시험준비 - 나만의 암기포인트 (0) | 2021.09.30 |
|---|---|
| 머신러닝 초보자를 위한 강의와 책 추천 (0) | 2021.08.26 |
| 개발자이직 알아볼 때 점핏(jumpit) 플랫폼 사용하면 편리해요! (0) | 2021.07.27 |
| JAVA와 객체지향프로그래밍 (0) | 2021.05.31 |
| Logistic Regression, kNN(k-Nearest Neighbor), Naive Bayes (0) | 2021.04.21 |
| 상관분석이란? 상관계수 결과 해석 (0) | 2021.04.19 |
| 평균 비교 검정/ Bartlett's Test - One Way ANOVA - Tukey's Range Test (0) | 2021.04.19 |
| 추론통계 기초 이해 및 Brightics를 사용한 t-test 결과 해석 (0) | 2021.04.19 |




댓글